Гайд по LLM (большим языковым моделям) в программировании / Skillbox Media
Рассказываем, как сориентироваться в запутанном мире сотен LLM с открытым исходным кодом.

Содержание:

Учитесь бесплатно: «Нейросети. Практический курс»
Узнать большеНесколько лет назад запуск новой языковой модели с открытым исходным кодом вызывал значительный резонанс в IT-сообществе. Однако сегодня этот процесс стал обыденным. Каждый месяц разрабатываются десятки новых опенсорсных моделей, а ежегодно их количество достигает сотен. Открытые языковые модели продолжают развиваться, привнося новые возможности и улучшая качество обработки естественного языка.
Для удобства навигации в разнообразии доступных нейронных сетей мы подготовили подробный гид, в котором представлены актуальные открытые модели. Этот ресурс поможет вам быстро найти нужные инструменты и технологии в области искусственного интеллекта.
Оптимизация текста для SEO требует не только изменения структуры, но и акцентирования внимания на ключевых словах и фразах, которые могут привлечь целевую аудиторию. Содержание должно быть информативным, релевантным и легко воспринимаемым.
Ниже приведён переработанный текст:
Содержание является важной частью любого контента, так как оно помогает пользователям быстро ориентироваться в материале. Правильно оформленный текст с ясным и логичным содержанием улучшает пользовательский опыт и способствует более высокому ранжированию в поисковых системах. Использование ключевых слов в заголовках и подзаголовках не только облегчает навигацию, но и делает текст более доступным для поисковых систем. Кроме того, актуальность и уникальность содержания играют ключевую роль в привлечении и удержании читателей. Создание качественного контента с чётким содержанием способствует формированию доверия к ресурсу и повышает его авторитет в глазах пользователей и поисковых систем.
Таким образом, содержание не просто структурирует информацию, но и становится основой для успешной SEO-стратегии.
- Откуда берутся опенсорсные модели
- Как они развиваются
- Какие у них есть преимущества и недостатки
- Какими бывают открытые LLM
- С какими видами open-source-лицензий их публикуют
- Как определить лучшие LLM
- На какие популярные опенсорсные модели стоит обратить внимание
- Что ещё почитать про открытые и проприетарные LLM
Откуда берутся открытые модели
Существует множество опенсорсных нейронных сетей. Однако большинство из них не являются независимыми проектами, а создаются на основе нескольких крупных языковых моделей (LLM), известных как базовые модели (foundation models). Эти базовые модели служат основой для разработки новых решений в области искусственного интеллекта и машинного обучения, позволяя исследователям и разработчикам создавать более специализированные приложения и инструменты.
Создание и обучение моделей ИИ требует значительных финансовых ресурсов и мощных вычислительных мощностей. Поэтому данная работа доступна преимущественно крупным научным коллективам и IT-компаниям, таким как Google и OpenAI. Например, обучение модели GPT-3 обошлось разработчикам почти в 5 миллионов долларов. Высокие затраты на обучение таких моделей обусловлены необходимостью обработки больших объемов данных и использования современных технологий, что делает процесс доступным не для всех организаций.
Базовая модель представляет собой искусственную нейросеть, которая прошла обучение на обширном объёме данных. Она может быть адаптирована для решения различных задач, что делает её универсальным инструментом в области машинного обучения. Настройка базовой модели позволяет повысить её эффективность и точность в выполнении конкретных задач, таких как обработка естественного языка, распознавание изображений и другие применения. Использование базовых моделей открывает новые возможности для разработки интеллектуальных систем и улучшения качества аналитики.
После завершения разработки новая модель может быть выпущена под закрытой (проприетарной) или открытой лицензией (опенсорсной). В случае открытой лицензии другие компании и независимые разработчики получают возможность доработать и адаптировать модель для решения специфических задач. Это способствует инновациям и повышению качества продукта, так как сообщество может вносить свои улучшения и оптимизации. Открытые лицензии также способствуют более широкому распространению технологий и их интеграции в различные решения.
Использование опенсорсных LLM не требует значительных финансовых вложений и вычислительных мощностей. Именно поэтому стартапы часто выбирают такие решения. Модифицированные версии моделей, созданные на основе исходного кода, принято называть форками (от английского слова fork — развилка). Это позволяет разработчикам адаптировать технологии под свои нужды, оптимизируя их для специфических задач и улучшая производительность.
К популярным базовым моделям, которые легли в основу открытых LLM, относятся:
- Цукерберговскую LLaMA и LLaMA 2, последняя из которых разработана совместно с Microsoft.
- BLOOM (BigScience large open-science open-access multilingual language model) от проекта BigScience, созданного при участии компании Hugging Face.
- GPT-2, выложенная OpenAI несколько лет назад, когда компания планировала разрабатывать только open-source-решения.
- Falcon — новейшая разработка от Института технологических инноваций (TII) из Абу-Даби (ОАЭ).
- Семейство моделей Т5 от компании Google.
Современные LLM-модели можно представить в виде генеалогического дерева, которое иллюстрирует их эволюцию и взаимосвязи. Эти языковые модели, основанные на глубоких нейронных сетях, развиваются с каждым годом, демонстрируя всё более сложные архитектуры и улучшенные алгоритмы. От первых простых моделей до современных мощных систем, таких как GPT и BERT, можно проследить, как каждая новая версия основывалась на предыдущих достижениях, интегрируя новые методы обработки естественного языка и обучения. Эволюция LLM-моделей не только обогащает их функционал, но и расширяет их применение в различных сферах, таких как автоматический перевод, создание контента и анализ данных. Благодаря этому, понимание генеалогии LLM-моделей становится важным для исследователей и разработчиков, стремящихся использовать их возможности в своих проектах.
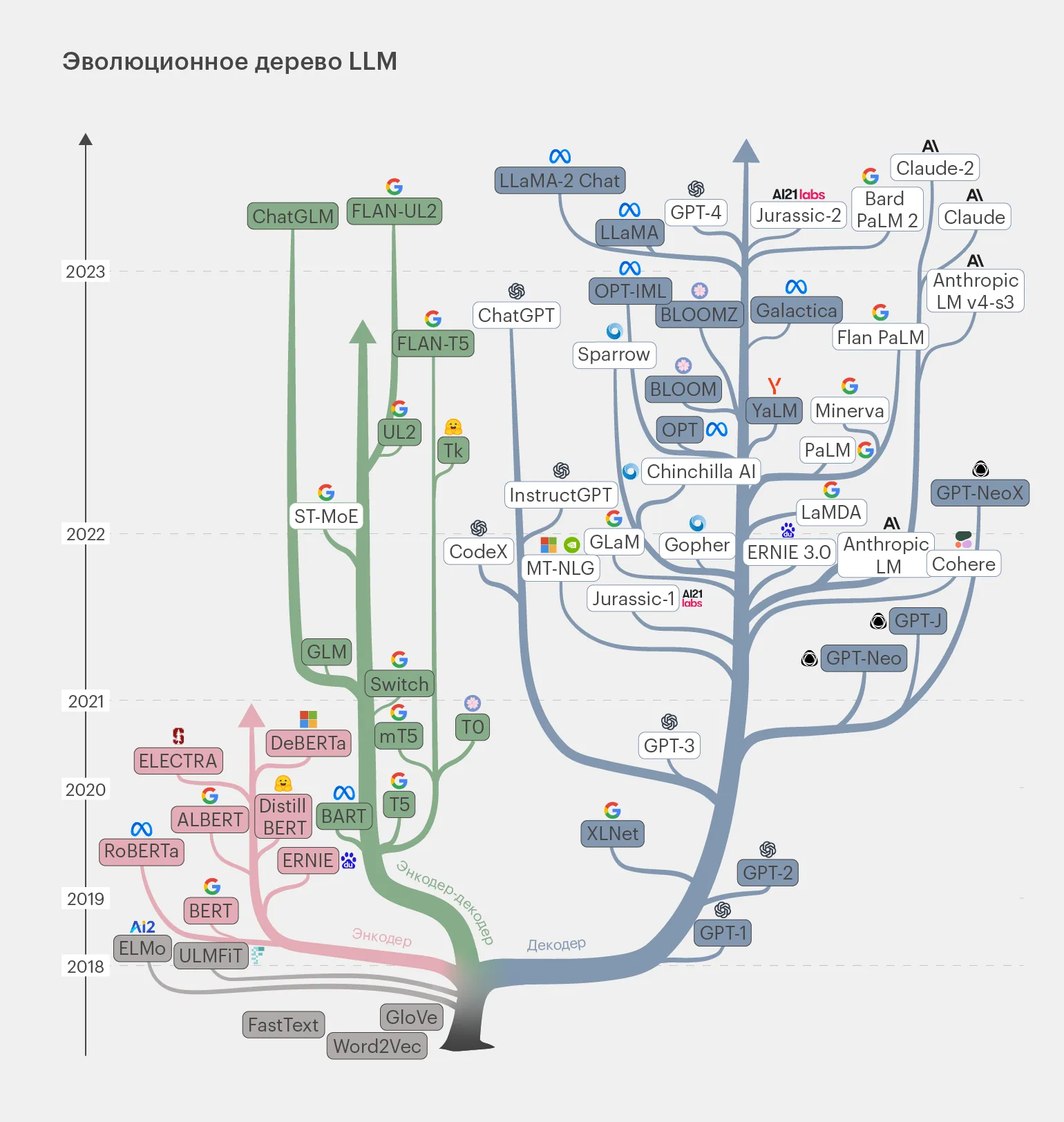
На данной схеме внимание уделяется моделям, представленным в закрашенных прямоугольниках. Эти модели представляют собой опенсорсные решения, которые мы обсудим сегодня. Мы рассмотрим их основные характеристики и эволюцию, достигнутую к 2023 году.
Как развиваются опенсорсные модели
У LLM с открытой лицензией наблюдаются те же проблемы, что и у проприетарных нейросетей, включая частые галлюцинации, ограничения по длине контекстного окна и необходимость обработки информации различных модальностей. Эти аспекты определяют схожесть направлений их развития. Таким образом, как открытые, так и закрытые модели сталкиваются с аналогичными вызовами, что подчеркивает важность дальнейших исследований и улучшений в этой области.
Снижение числа галлюцинаций в языковых моделях. Языковые модели, такие как LLM, могут генерировать ошибочные данные, которые кажутся правдоподобными. Эти ошибки называют галлюцинациями. На сегодняшний день полностью устранить такие неточности в ответах нейросетей не удалось. Улучшение алгоритмов и методов обучения продолжается, но задача по минимизации галлюцинаций остается актуальной для разработчиков.
Лидер в борьбе с галлюцинациями — закрытая модель GPT-4, демонстрирующая ошибку лишь в 3% случаев. Однако на уровне точности ей близка опенсорсная модель LLaMA 2 70B, которая по своим показателям сравнима с хорошо известной проприетарной моделью Gemini от Google DeepMind. Оба решения представляют собой передовые технологии в области обработки естественного языка, и их эффективность делает их ценными инструментами для различных приложений.
Увеличение длины контекстного окна — важный фактор, влияющий на производительность и качество ответов языковых моделей (LLM). Чем больше объём текста, который модель может обработать, тем более информированные и точные ответы она способна генерировать. Это обусловлено тем, что при расширении контекстного окна значительно увеличивается количество данных, доступных для анализа, что, в свою очередь, улучшает контекстуальное понимание и снижает вероятность ошибок. Таким образом, увеличение длины контекстного окна является ключевым шагом в повышении эффективности работы LLM и улучшении качества взаимодействия с пользователями.
Закрытые модели GPT-4 и Claude 100K демонстрируют способность обрабатывать более 100 тысяч токенов одновременно, что значительно расширяет их функциональные возможности. В то же время нейросети с открытым кодом активно развиваются, стремясь достичь аналогичных показателей в области обработки информации. Эти достижения открывают новые горизонты для применения искусственного интеллекта в различных сферах, включая анализ данных, создание контента и автоматизацию процессов. Интерес к улучшению моделей с открытым кодом растет, что способствует глобальному прогрессу в сфере разработки нейросетей.
Базовая модель Mistral 7B обеспечивает обработку 8000 токенов, в то время как её современный форк Nous-Yarn-Mistral-7B-128k от компании Nous Research значительно расширяет возможности, поддерживая контекстное окно до 128 тысяч токенов. Это значительное улучшение позволяет моделям более эффективно обрабатывать и анализировать большие объемы текстовой информации, что открывает новые горизонты в области обработки естественного языка и машинного обучения.
Обработка данных различных модальностей. Современные нейросети способны эффективно работать не только с текстовой информацией, но и с изображениями, видео и аудио. Эта функциональность уже внедрена в несколько опенсорсных LLM, что расширяет их применение в разных областях, таких как компьютерное зрение, распознавание речи и мультимедийный анализ. Благодаря мультидоменному подходу, нейросети могут анализировать и интегрировать данные из разных источников, что значительно повышает их функциональность и точность.
- зрительно-языковой модели Nous-Hermes-2-Vision-Alpha;
- мультимодальной нейросети Qwen-VL от китайской компании Alibaba Cloud;
- мультимодальной версии LLaMA с названием LLaVA-13B.

Снижение стоимости разработки LLM. Одной из основных проблем, связанных с нейросетями, является высокая цена создания базовых моделей. Однако благодаря тому, что некоторые из них доступны под открытыми лицензиями, расходы на дообучение и внедрение значительно уменьшаются. Например, доработка и запуск опенсорсных моделей Alpaca и Vicuna-13B, основанных на LLaMA, обошлись разработчикам всего в 600 и 300 долларов соответственно. Это делает нейросети более доступными для разработчиков и способствует их более широкому применению в различных областях.
Одним из эффективных способов снижения затрат является применение нейросетей для генерации синтетических обучающих данных, а также для оценки качества работы новых моделей. Этот метод известен как RLAIF (обучение с подкреплением с обратной связью от ИИ) и позволяет оптимизировать процесс обучения, улучшая результаты и сокращая время разработки. Использование RLAIF способствует повышению эффективности и снижению риска ошибок, что делает его важным инструментом в современных технологиях машинного обучения.
Запуск языковых моделей на слабом железе становится все более доступным. Большинство языковых моделей с открытым исходным кодом имеют меньше параметров, чем их закрытые аналоги. Это позволяет эффективно использовать такие модели на устройствах с ограниченными ресурсами, включая домашние компьютеры. Пользователи могут легко интегрировать и тестировать эти нейронные сети, что открывает новые возможности для разработки и экспериментов в области обработки естественного языка.
Mistral 7B обладает значительно меньшим количеством параметров по сравнению с GPT-3.5, составляя всего 25% от её объема. Это приводит к снижению требований к вычислительным ресурсам: Mistral 7B требует примерно в 187 раз меньше мощностей, чем GPT-4, и в девять раз меньше, чем GPT-3.5. Это делает Mistral 7B более доступным решением для разработчиков и компаний, стремящихся использовать возможности искусственного интеллекта без значительных затрат на вычислительные ресурсы.

Научный сотрудник группы «Вычислительная семантика» Института искусственного интеллекта AIRI занимается исследованиями в области обработки естественного языка и разработки методов, позволяющих машинам понимать и интерпретировать смысл текстов. Основное внимание уделяется созданию алгоритмов, которые способны анализировать семантические связи между словами и фразами, что является ключевым аспектом в развитии интеллектуальных систем. Работа в данной группе способствует внедрению передовых технологий в различных сферах, таких как автоматический перевод, системы вопросов и ответов, а также в области анализа данных.
Опенсорсные модели предоставляют бизнесу возможность использовать LLM с минимальными ограничениями. Открытые решения позволяют компаниям полностью контролировать процессы обработки данных пользователей, адаптировать их под специфические требования и значительно снизить риски, используя собственную инфраструктуру. Это делает опенсорсные технологии привлекательными для предприятий, стремящихся к повышению безопасности и эффективности управления данными.
Появление опенсорсных моделей стало значительным фактором в повышении уровня компетенций академического сообщества в области работы с языковыми моделями (LLM). Сегодня уже никого не удивляет чат-бот, подобный ChatGPT, который может быть запущен на ноутбуке энтузиастом. Всего два года назад это казалось невозможным. Развитие технологий и доступность инструментов открывают новые возможности для исследований и разработок в сфере искусственного интеллекта, что подстёгивает интерес и активность как специалистов, так и любителей.
Улучшение существующих и разработка новых архитектур нейросетей является актуальной задачей в сфере искусственного интеллекта. Одной из ключевых проблем больших языковых моделей (LLM) являются ограничения архитектуры трансформеров, что приводит к различным недостаткам в их работе. Решения этой проблемы ожидаются от стартапов, которые занимаются открытыми моделями и активно экспериментируют с их внутренней структурой. Инновации в архитектурах нейросетей могут значительно повысить эффективность и производительность моделей, что в свою очередь позволит расширить их применение в различных областях.
Архитектура Mixture of Experts (MoE, «модель смешанных экспертов») может стать решением для повышения эффективности моделей, подобных GPT-4. Эта архитектура включает восемь нейросетей-экспертов, каждая из которых специализируется на определённых задачах. Опенсорсная модель Mixtral 8x7B, разработанная французской компанией Mistral AI, демонстрирует в шесть раз большую скорость генерации ответов по сравнению с исходной моделью LLaMA 2 70B. Использование MoE позволяет значительно оптимизировать производительность и адаптивность нейросетей, что особенно важно для создания высококачественного контента и улучшения пользовательского опыта.
Построение мультиагентных систем на основе языковых моделей (LLM) представляет собой инновационный подход к улучшению качества работы нейросетей. В отличие от изменения архитектуры, этот метод фокусируется на создании систем, состоящих из множества независимых агентов, которые способны взаимодействовать и договариваться друг с другом. Такой подход позволяет эффективно решать сложные задачи пользователей, используя коллективный интеллект нескольких нейросетей. Мультиагентные системы способны адаптироваться к различным сценариям, что делает их особенно полезными в сфере обработки естественного языка и других областях, где требуется гибкость и динамичность в решении задач.
Идеальными кандидатами для использования в таких системах являются открытые LLM, которые не требуют значительных вычислительных ресурсов. На сегодняшний день уже существуют проекты, такие как AutoGPT, GPT-Engineer, LangChain и GPTeam, которые успешно реализуют эти технологии. Открытые LLM обеспечивают доступность и гибкость в разработке, позволяя пользователям эффективно использовать возможности искусственного интеллекта без необходимости в дорогостоящем оборудовании.
Создание больших языковых моделей (LLM) для языков, отличных от английского, представляет собой сложную задачу. Нейросети чаще всего используют английский язык, так как именно на нём основана значительная часть обучающих данных. Это приводит к тому, что другие языки, на которых говорят десятки и сотни миллионов людей, оказываются в менее выгодном положении. Обучение моделей для работы с такими языками требует значительных усилий по поиску и созданию качественных датасетов, что в свою очередь подразумевает дополнительные ресурсы и время. Таким образом, развитие LLM для различных языков становится важной задачей, которая потребует внимания и инвестиций для достижения равноправия в обработке языковых данных.
Несмотря на мощь современных нейронных сетей, таких как GPT-4, они поддерживают лишь несколько сотен языков из более чем 7000 существующих. Специалисты уверены, что решение этой проблемы может быть найдено в опенсорсных языковых моделях (LLM). Разработка доступных и многоязычных LLM может значительно расширить языковые возможности, позволяя большему числу людей получить доступ к передовым технологиям обработки естественного языка.
В 2023 году была представлена новая модель Jais, разработанная в ОАЭ, которая умеет общаться на арабском языке. Также был анонсирован вариант LLaMA, адаптированный для португальского языка. В России компании «Яндекс» и «Сбер» выпустили нейронные сети YaLM 100B и ruGPT-3.5 13B, ориентированные на русский язык. Эти разработки подчеркивают активное развитие технологий искусственного интеллекта и их адаптацию к различным языкам, что открывает новые возможности для пользователей по всему миру.
Продолжается работа над редкими языками. В 2023 году стартовал проект Massively Multilingual Speech (MMS), целью которого является создание наборов данных для 1100 языков, которые ранее не имели достаточного покрытия. Этот проект направлен на расширение возможностей обработки речи и улучшение технологий в области автоматического распознавания речи для множества языков, что значительно повысит доступность информации и услуг для носителей этих языков.

Читать также:
Тигр и дракон: проекты и перспективы Китая в области генеративного ИИ
Китай активно развивает технологии генеративного искусственного интеллекта, стремясь занять лидирующие позиции в этой быстроразвивающейся отрасли. Синергия мощных вычислительных ресурсов и богатых данных позволяет стране разрабатывать инновационные решения, которые меняют подход к искусственному интеллекту.
Китайские компании и исследовательские учреждения работают над созданием передовых моделей, способных генерировать текст, изображения и даже музыку. Эти разработки открывают новые горизонты для различных секторов экономики, включая образование, здравоохранение и развлечения.
Государственная поддержка и инвестиции в стартапы играют ключевую роль в ускорении роста индустрии. Китайские предприятия активно сотрудничают с международными партнёрами, что способствует обмену знаниями и технологиями.
Перспективы генеративного ИИ в Китае кажутся многообещающими: от создания персонализированных решений для пользователей до автоматизации бизнес-процессов. Ожидается, что в ближайшие годы страна сделает значительный вклад в мировую экосистему искусственного интеллекта.

Научный сотрудник группы «Вычислительная семантика» Института искусственного интеллекта AIRI занимается исследованием и разработкой алгоритмов, которые позволяют компьютерам понимать и обрабатывать естественный язык. Основной целью работы является создание моделей, способных анализировать семантическое значение текста, что открывает новые горизонты для применения искусственного интеллекта в различных сферах, таких как автоматический перевод, обработка данных и взаимодействие человек-компьютер. Специалисты в этой области активно участвуют в междисциплинарных проектах, способствующих развитию технологий и улучшению качества взаимодействия с информационными системами.
Опенсорсные модели открывают новые возможности для бизнеса, позволяя эффективно использовать LLM без значительных ограничений. Открытые решения предоставляют компаниям полный контроль над процессом обработки данных пользователей, что способствует их адаптации под специфические потребности бизнеса. Это не только повышает гибкость, но и существенно снижает риски, так как компании могут использовать собственную инфраструктуру для обработки и хранения информации. Таким образом, опенсорсные технологии становятся важным инструментом для обеспечения безопасности и оптимизации работы с данными в современном бизнесе.
Появление опенсорсных моделей значительно повысило уровень компетенций в академическом сообществе в области работы с большими языковыми моделями (LLM). В настоящее время чат-боты, аналогичные ChatGPT, разработанные энтузиастами на обычных ноутбуках, уже не вызывают удивления. Это достижение, которое еще два года назад воспринималось как фантастика, свидетельствует о быстром прогрессе технологий и доступности инструментов для разработчиков и исследователей.
Преимущества и недостатки открытых LLM
Компании выбирают опенсорсные нейросети благодаря их многочисленным преимуществам по сравнению с проприетарными моделями. Во-первых, опенсорсные решения обеспечивают большую гибкость и возможность кастомизации, что позволяет адаптировать модели под специфические потребности бизнеса. Во-вторых, они способствуют сокращению затрат, так как не требуют лицензирования и дополнительных платежей за использование. В-третьих, доступность исходного кода позволяет разработчикам вносить изменения и улучшения, а также легко интегрировать нейросети в существующие системы. Кроме того, сообщество разработчиков активно поддерживает такие проекты, что способствует быстрому решению проблем и обмену знаниями. Наконец, опенсорсные нейросети обеспечивают высокий уровень прозрачности, что позволяет компаниям лучше контролировать процессы и результаты работы моделей. Таким образом, выбор в пользу опенсорсных нейросетей становится все более обоснованным для организаций, стремящихся к инновациям и оптимизации своих процессов.
- Безопасность и конфиденциальность данных. LLM с открытым исходным кодом можно развернуть на собственной инфраструктуре без пересылки информации на сторонние серверы. Благодаря этому пользователи получают полный контроль над данными, которые обрабатывает нейросеть.
- Экономия средств. Опенсорсные LLM можно использовать без оплаты подписки или регулярных выплат разработчикам по контрактам. Поэтому они популярны у стартапов и компаний с ограниченным бюджетом.
- Снижение зависимости от поставщиков IT-услуг. Пользователи могут выбрать наиболее подходящий для себя вариант нейронок из сотен опенсорсных LLM. Таким образом, компания не привязывается к одному поставщику ИИ-решений и может выбирать лучшие модели или даже сочетать их между собой.
- Прозрачность используемых LLM. Модели с открытым исходным кодом можно изучить изнутри и понять, как именно они работают с данными. Это позволяет выявить и предотвратить отправку информации на сторонние серверы.
- Проекты с открытым исходным кодом поддерживаются группами разработчиков и экспертов. Благодаря этому возникшие баги и проблемы быстро устраняются, а документация подробно описывает нюансы использования нейросети. Это характерно для большинства опенсорсных моделей, но есть и неприятные исключения.
- Нестандартные решения и подходы. Открытые LLM позволяют экспериментировать с ИИ, опираясь на новые базовые модели. Даже небольшие стартапы могут творчески перерабатывать такие нейросети и использовать их в качестве основы для собственных уникальных разработок.

Генеральный директор компании «Аватар Машина», разработчик чат-бота-психолога «Сабина Ai» и соавтор проекта FractalGPT, представляет собой профессионала в области технологий и искусственного интеллекта. Под его руководством компания достигла значительных успехов в создании инновационных решений, направленных на поддержку и развитие эмоционального интеллекта с помощью современных цифровых инструментов. Чат-бот «Сабина Ai» предлагает пользователям доступ к психологической помощи и консультациям, используя передовые алгоритмы обработки естественного языка. Проект FractalGPT, в свою очередь, демонстрирует возможности глубокого обучения и генерации текста, что открывает новые горизонты в области взаимодействия человека и машины.
Массовое появление и распространение больших языковых моделей с открытой лицензией обусловлено глобальным трендом на повышение производительности и снижение затрат на LLM. В настоящее время потребители стремятся отказаться от закрытых проприетарных решений, которые создают зависимость от зарубежных поставщиков и политической нестабильности. Эти факторы способствуют отказу от использования решений таких известных иностранных IT-гигантов, как OpenAI. Открытые языковые модели предоставляют пользователям большую гибкость и контроль, что делает их все более привлекательными в условиях современных вызовов.
Опенсорсные LLM имеют свои недостатки. Во-первых, такие модели могут страдать от ограничений в качестве данных. Часто они обучаются на менее разнообразных и менее качественных наборах данных, что может негативно сказаться на их производительности и точности. Во-вторых, отсутствие коммерческой поддержки может создать проблемы с обновлениями и исправлениями ошибок, что может привести к уязвимостям. Также, опенсорсные LLM могут иметь меньшую степень оптимизации и настройки по сравнению с проприетарными решениями, что может ограничивать их применение в специфических задачах. Наконец, использование опенсорсных LLM требует наличия технических навыков для их настройки и интеграции, что может быть барьером для некоторых пользователей.
- Их внедрение и обслуживание может потребовать больше времени и технических знаний от специалистов, чем при использовании проприетарных моделей. Последние обычно готовы к работе «из коробки».
- Разработки от малоизвестных коллективов могут быть обучены на неполных или некачественных данных. Это снижает точность ответов нейросети и повышает частоту галлюцинаций.
- У опенсорсных моделей возможны недокументированные проблемы в работе. Например, отсутствие совместимости между разными версиями LLM.

Генеральный директор ООО «А-Я эксперт» — компании, специализирующейся на разработке систем искусственного интеллекта. Мы фокусируемся на создании инновационных решений в области ИИ, которые помогают бизнесам оптимизировать процессы и повышать эффективность. Наша команда экспертов разрабатывает передовые технологии, способствующие автоматизации и аналитике данных. Мы стремимся быть лидерами в индустрии искусственного интеллекта, предлагая клиентам уникальные и высококачественные продукты.
Опенсорсные LLM должны быть открытыми не только в плане исходного кода моделей, но и в отношении данных, на которых они обучаются. Это ключевой аспект, поскольку проблема «отравления данных» продолжает оставаться актуальной. Важно обеспечить чистоту и прозрачность данных, чтобы гарантировать надежность и безопасность моделей. Современные разработки будут сосредоточены на решении этих вопросов, что повысит доверие пользователей и улучшит качество результатов, получаемых от LLM.
Инженеры, учёные и государственные организации сталкиваются с вопросами доверия к данным при использовании решений на основе открытых моделей искусственного интеллекта. Для успешной интеграции опенсорсных моделей в соответствующий рыночный сегмент необходимы открытость и высокое качество датасетов, на которых обучаются нейросети. Это позволит повысить уровень доверия к технологиям и обеспечить их более широкое применение в различных отраслях.

Читайте также:
Открытое и свободное программное обеспечение (Open Source) привлекает внимание благодаря своей доступности и прозрачности. Однако за его преимуществами скрываются определенные риски. Одной из основных опасностей является возможность внедрения вредоносного кода. Поскольку исходный код доступен всем, злоумышленники могут воспользоваться уязвимостями для создания эксплойтов. Кроме того, отсутствие централизованной поддержки может привести к проблемам с безопасностью, так как обновления и патчи не всегда выпускаются своевременно.
Также стоит учитывать проблемы совместимости и зависимости. Использование открытого ПО может вызвать конфликты между различными библиотеками, что усложняет процесс разработки и поддержки. Отсутствие профессиональной поддержки может оставить пользователей без необходимых ресурсов для устранения проблем, что негативно сказывается на бизнес-процессах.
Не стоит забывать и о юридических аспектах. Лицензии на открытое ПО могут содержать условия, которые ограничивают его использование в коммерческих целях, что может привести к правовым последствиям для организаций.
Таким образом, несмотря на привлекательность открытого и свободного программного обеспечения, важно тщательно оценивать связанные с ним риски и принимать меры для их минимизации. Убедитесь, что вы понимаете условия лицензирования, обеспечиваете безопасность кода и готовы к потенциальным проблемам с поддержкой.

Генеральный директор компании «Аватар Машина», разработчик чат-бота-психолога «Сабина Ai» и соавтор проекта FractalGPT. Ведущий эксперт в области искусственного интеллекта и автоматизации, с опытом создания инновационных решений для поддержки психологического здоровья. Стратегически ориентирован на развитие технологий, которые помогают улучшить качество жизни пользователей через доступные и эффективные инструменты.
Массовое внедрение и распространение больших языковых моделей с открытой лицензией обусловлено глобальным трендом на повышение производительности и снижение затрат на LLM. Современные потребители стремятся отказаться от закрытых проприетарных решений, ведь это создает зависимость от зарубежных поставщиков и политических факторов. Именно эти обстоятельства побуждают пользователей искать альтернативы популярным решениям иностранных IT-гигантов, таких как OpenAI. Открытые языковые модели позволяют избежать рисков, связанных с внешними угрозами, и предоставляют большую гибкость в использовании технологий обработки естественного языка.

Генеральный директор ООО «А-Я эксперт», компании, специализирующейся на разработке систем искусственного интеллекта, играет ключевую роль в создании инновационных решений в данной области. Под его руководством компания разрабатывает передовые технологии, которые помогают оптимизировать бизнес-процессы и повышать эффективность работы различных организаций. Системы искусственного интеллекта, разработанные компанией, применяются в различных отраслях, включая финансы, здравоохранение и производство, что подтверждает их универсальность и востребованность на рынке.
Опенсорсные LLM должны быть открытыми как в отношении исходного кода, так и данных, на которых они обучаются. Это особенно важно в свете проблемы «отравления данных», которая продолжает оставаться актуальной. В настоящее время акцент смещается на обеспечение чистоты и прозрачности данных, что является ключевым аспектом для повышения доверия к моделям. Открытость в этих областях способствует не только улучшению качества обучения, но и снижению рисков, связанных с использованием некорректной информации.
Инженеры, ученые и государственные структуры сталкиваются с важными вопросами доверия к данным при использовании решений, основанных на открытых моделях искусственного интеллекта. Для того чтобы опенсорсные модели смогли занять свою нишу на рынке, необходимы высокая степень открытости и качественные датасеты, на которых происходит обучение нейросетей. Это позволит повысить уровень доверия к результатам работы таких моделей и обеспечит их конкурентоспособность в различных сферах.
Какими бывают открытые LLM
Модели с открытым кодом классифицируются по нескольким параметрам, включая степень обученности, размер и поддержку различных языков. Рассмотрим каждый из этих аспектов более подробно.
Разработчики часто публикуют в открытом доступе только предобученные версии своих нейронных сетей, известные как «претрейны». К примеру, специалисты компании «Сбер» сделали доступной отечественную модель ruGPT-3.5, а также аналогично поступил Марк Цукерберг с исходной моделью LLaMA. Такие решения позволяют исследователям и разработчикам использовать уже готовые решения для дальнейших экспериментов и доработок, что способствует развитию технологий искусственного интеллекта и расширяет возможности их применения в различных сферах.
Языковые модели перед публикацией проходят длительный процесс обучения на обширных объемах неразмеченных текстовых данных. Этот процесс требует значительных вычислительных ресурсов и финансовых вложений. В результате нейронные сети формируют общее понимание языка, что позволяет им эффективно обрабатывать и генерировать текст.
Использование «претрейн» для решения конкретных задач может быть затруднительным. Он в основном предназначен для генерации продолжений текстовых последовательностей, которые вводит пользователь. К примеру, система может легко завершить фразу, начинающуюся с определения: «Машинное обучение — это…». Однако для более сложных задач требуется дополнительная настройка и адаптация.
Если пользователь попытается начать диалог с нейросетью или даст ей инструкции для выполнения действий, то нейросеть может начать генерировать неуместные или бессмысленные ответы вместо предоставления полезной информации. Это может привести к недопониманию и снижению доверия к технологии, что подчеркивает важность дальнейшего развития и обучения нейросетей для повышения качества взаимодействия с пользователями.
Популярность современных языковых моделей объясняется не претрейнами, а базовыми моделями, которые прошли дополнительную настройку, известную как «файн-тюнинг» (fine tuning). Обычно в названиях таких LLM содержится слово Chat, если нейросеть была дообучена для ведения диалогов, или Instruct, если она способна выполнять инструкции с использованием метода, аналогичного RLHF, применённого при обучении ChatGPT. Файн-тюнинг значительно улучшает качество взаимодействия с пользователем и расширяет функциональные возможности моделей, что делает их более востребованными в различных приложениях, связанных с обработкой естественного языка.
Существуют и более узкоспециализированные варианты дообучения моделей. Например, модель MPT-7B представлена в версии StoryWriter, которая ориентирована на создание вымышленных историй с длинным контекстом. Также стоит отметить множество языковых моделей, которые генерируют программный код. В названиях таких нейронных сетей часто встречается слово «Code», как в случаях с StableCode, CodeGeneX и другими подобными решениями. Эти модели демонстрируют высокую эффективность в автоматизации программирования и упрощении разработки программного обеспечения.
По данному критерию LLM (Large Language Models) можно разделить на три основные категории.
- англоязычные;
- с поддержкой одного местного языка, например русского;
- мультиязычные, которые справляются сразу с несколькими языками, отличными от английского.
При использовании нейросетей в России важно учитывать поддержку русского языка, поскольку это значительно улучшает взаимодействие пользователей с технологиями. Однако основным языком для большинства моделей остается английский, что может создавать определенные трудности для русскоязычных пользователей. Успешная интеграция нейросетей в российский рынок требует разработки и адаптации моделей, способных эффективно работать с русским языком и учитывать культурные особенности.
Это связано с тем, что именно на этом языке доступно наибольшее количество данных, необходимых для обучения нейронных сетей. Другие языки требуют дополнительных тренировок и модификаций архитектуры для достижения сопоставимых результатов. Поскольку разнообразие данных критически важно для эффективного обучения моделей, использование этого языка обеспечивает значительное преимущество в разработке и оптимизации нейронных сетей.
Практически все опенсорсные модели способны обрабатывать русский язык. Однако, основная проблема заключается в том, что большинство популярных языковых моделей (LLM) разрабатывались с учетом английского языка или, по крайней мере, латиницы. Это приводит к тому, что тексты на кириллице занимают больше места в токенах, что, в свою очередь, значительно сокращает контекст использования моделей. Оптимизация токенизаторов для кириллицы могла бы улучшить качество обработки русского языка в опенсорсных моделях.
Михаил Сальников – это имя, которое ассоциируется с профессионализмом и высоким уровнем экспертизы в своей области. Благодаря многолетнему опыту работы, Михаил стал признанным специалистом, способным решать сложные задачи и находить эффективные решения. Его подход к делу основывается на глубоком анализе и внимании к деталям, что позволяет достигать отличных результатов в работе. Михаил активно делится своими знаниями и опытом, что помогает другим развиваться и достигать успеха в своей сфере.
Современные тенденции в области нейросетей показывают, что размер модели не всегда определяет ее эффективность. Опенсорсные нейросети, даже с небольшими размерами, способны демонстрировать результаты, сопоставимые с крупными проприетарными системами. При выборе языковой модели (LLM) важно ориентироваться на баланс между размером и производительностью — модель должна быть достаточно компактной для решения конкретных задач, при этом обеспечивая необходимую функциональность и качество.
Каждая модель может быть оценена с использованием регулярно обновляемых метрик качества, известных как бенчмарки. На основе этих показателей все LLM (Large Language Models) можно классифицировать на две основные категории.
- Модели, которые демонстрируют результаты, близкие к некому «качеству отсечения». Как правило, базовым уровнем считается ChatGPT (GPT-3.5-Turbo).
- Модели, которые не удовлетворяют соотношению цена — качество. Это либо слишком большие LLM, стоимость которых зашкаливает, либо очень маленькие, содержащие менее 7 миллиардов параметров. Последние обычно имеют провалы в качестве работы, обнаруживаемые с помощью отдельных бенчмарков, связанных с пониманием языка».
Виктор Носко – известный профессионал в своей области. Он обладает значительным опытом и глубокими знаниями, что позволяет ему эффективно решать сложные задачи. Его подход к работе всегда основан на высоких стандартах качества и внимании к деталям. Виктор активно делится своими знаниями с коллегами и молодыми специалистами, способствуя развитию профессионального сообщества. Его стремление к постоянному обучению и самосовершенствованию делает его ценным активом в любой команде. Благодаря своей преданности делу и высокой квалификации, Виктор Носко зарекомендовал себя как надежный партнер и эксперт в своей области.
Вторым важным параметром, касающимся размера модели, является тип LLM: полная или квантованная. Квантование нейросети позволяет значительно снизить требования к вычислительной мощности и объему оперативной памяти. Однако стоит отметить, что при этом происходит снижение точности работы языковой модели. Выбор между полной и квантованной версией зависит от задач, которые необходимо решить, и от доступных ресурсов. Полные LLM обеспечивают более высокую точность и качество обработки, тогда как квантованные варианты подходят для применения в условиях ограниченных вычислительных ресурсов.
Конечно, я готов помочь с редактированием текста. Пожалуйста, предоставьте сам текст, который нужно переработать.
Снижение стоимости хостинга модели часто достигается за счет квантования. Это позволяет запускать модель даже на стандартных домашних видеокартах, таких как GTX или RTX 3070–3090 от NVIDIA. Однако стоит отметить, что при таком подходе качество работы модели может снизиться на 5–15% по сравнению с оригинальной версией. В некоторых случаях это снижение качества оказывается приемлемым для пользователей.
Виктор Носко — это имя, которое стало символом профессионализма и качества в своей области. Он зарекомендовал себя как эксперт, предлагающий уникальные решения и идеи. Благодаря своему опыту и навыкам, Виктор Носко привлекает внимание не только клиентов, но и коллег по отрасли.
В своей работе Виктор Носко акцентирует внимание на инновациях и эффективности, что позволяет ему достигать высоких результатов. Ключевым аспектом его подхода является постоянное стремление к саморазвитию и обучению, что делает его востребованным специалистом.
Виктор Носко активно делится своими знаниями и опытом, проводя мастер-классы и семинары. Это позволяет ему не только укреплять свои позиции на рынке, но и создавать сообщество профессионалов, готовых к обмену идеями и опытом.
Успех Виктора Носко объясняется не только его высоким профессионализмом, но и умением находить общий язык с клиентами, что способствует долгосрочным партнерским отношениям. Его работа ориентирована на результат и удовлетворение потребностей клиентов, что является залогом успеха в конкурентной среде.
Виктор Носко — это не просто имя, а бренд, который ассоциируется с надежностью и качеством.
Основные виды open-source-лицензий
Не все открытые модели являются одинаково доступными. Степень открытости зависит от лицензии, выбранной разработчиком. Некоторые лицензии предоставляют полную свободу использования и модификации, в то время как другие могут накладывать ограничения. Важно внимательно изучить лицензионные условия, чтобы понять, какие возможности и ограничения предоставляет конкретная опенсорсная модель.
Частично открытые модели имеют ряд значительных ограничений на применение. Например, разработчики LLaMA 2 требуют от пользователей принятия соглашения с обширным перечнем условий и запретов перед загрузкой. Одним из основных требований является запрет на использование нейросети в проектах, где количество пользователей превышает 700 миллионов в месяц. Более того, результаты работы LLaMA 2 не могут быть использованы для обучения других языковых моделей, за исключением самой LLaMA и её производных. Это подчеркивает важность соблюдения лицензионных условий при работе с нейросетями.
Большинство крупных языковых моделей (LLM) распространяется по лицензиям свободного программного обеспечения. Основные из них включают следующие типы лицензий:
- Apache 2.0 позволяет использовать модели для любых целей, модифицировать их и распространять в соответствии с условиями лицензии, без отчисления платежей разработчику. Под этой лицензией создано подавляющее большинство открытых LLM: T5, Mistral 7B и другие.
- MIT License разработана Массачусетским технологическим институтом (MIT). Во многом совпадает с Apache 2.0, но допускает повторное использование опенсорсного кода в составе проприетарного ПО. Например, эта лицензия используется для модели Phi-2 от Microsoft.
- Open RAIL-M v1 поддерживается сообществом BigCode, созданным компанией Hugging Face. Лицензия предполагает свободный доступ к моделям, возможность модификации их исходного кода, и совместное использование LLM и их вариантов. Содержит ряд ограничений, связанных с запретом на использование в неэтичной или противоправной деятельности. Под этой лицензией распространяется модель BLOOM.
- CC BY-SA 4.0 поддерживается международной некоммерческой организацией Creative Commons. Позволяет копировать и распространять LLM, модифицировать и дополнять их для любых целей, включая коммерческое использование. Но в последнем случае распространять новые модели следует по той же лицензии, что и оригинал. Под этой лицензией находится модель MPT-7B-Chat.
- BSD-3-Clause. Лицензия свободного ПО с минимальными ограничениями на использование и распространение нейросеток. Допускает неограниченное копирование для любых целей при условии указания дисклеймеров об авторских правах и отказа от гарантийных обязательств. Используется редко. Нам удалось найти одну популярную LLM с подобной лицензией — CodeT5+.

Для улучшения видимости в поисковых системах важно оптимизировать текст, сохраняя его основное содержание. Мы предлагаем вам ознакомиться с актуальной информацией по интересующей вас теме. Убедитесь, что ваш контент привлекателен и полезен для читателей, что способствует увеличению трафика на ваш сайт.
Постоянное обновление и дополнение материалов поможет поддерживать интерес аудитории и улучшать позиции в поисковых системах. Не забывайте следить за актуальными трендами и изменениями в тематике, чтобы оставаться на шаг впереди.
Читайте также:
Лицензии BSD и MIT: основные различия и сферы применения
Лицензии BSD и MIT являются популярными открытыми лицензиями, которые используются в разработке программного обеспечения. Обе лицензии позволяют пользователям свободно использовать, изменять и распространять программное обеспечение. Однако есть некоторые ключевые различия между ними, которые могут повлиять на выбор лицензии для вашего проекта.
Лицензия BSD, исходно разработанная в Университете Беркли, включает несколько вариантов, включая 2-пунктную и 3-пунктную версии. Основные положения обеих версий позволяют пользователям использовать код как угодно, при этом важно сохранить уведомление об авторских правах и отказ от ответственности. 3-пунктная версия добавляет требование о том, что название проекта не может использоваться для рекламы без разрешения.
Лицензия MIT, в свою очередь, более лаконична и проста. Она разрешает любое использование кода, при условии сохранения уведомления об авторских правах и лицензии в копиях программного обеспечения. MIT обычно считается более простой для понимания и использования, что делает её популярной среди разработчиков.
Обе лицензии широко используются в различных проектах, от небольших библиотек до крупных программных комплексов. Например, проекты на GitHub часто выбирают MIT за его простоту, в то время как более крупные проекты, такие как FreeBSD и OpenBSD, используют BSD для обеспечения большей гибкости в использовании.
Выбор между лицензиями BSD и MIT зависит от особенностей вашего проекта и требований к лицензированию. При принятии решения стоит учитывать как юридические аспекты, так и предпочтения сообщества разработчиков.
Как найти лучшую LLM
Для определения наиболее эффективной опенсорсной языковой модели (LLM) специалисты разработали виртуальные тестовые арены, известные как лидерборды. На этих платформах языковые модели конкурируют друг с другом, что позволяет оценить их производительность и выявить сильные и слабые стороны каждой из них.
На платформах, посвященных оценке нейросетей, каждая модель анализируется по ряду метрик качества, известных как бенчмарки. Важно отметить, что не существует идеальной языковой модели, которая бы превосходила по всем показателям. Модель может показывать отличные результаты по одному критерию, однако при этом демонстрировать низкие результаты по другим метрикам. Это подчеркивает необходимость комплексного подхода к оценке нейросетей, чтобы получить полное представление о их возможностях и ограничениях.
При выборе LLM важно ориентироваться на метрики, которые наилучшим образом соответствуют поставленной задаче. Большинство тестовых арен предлагает удобный интерфейс, позволяющий сортировать доступные модели по интересующим параметрам. Это позволяет быстро находить оптимальные решения и эффективно использовать возможности каждой модели.
Рекомендуем обратить внимание на несколько популярных лидербордов. Это поможет вам выбрать наиболее подходящий вариант и оценить позиции различных участников в определенной области. Лидерборды служат отличным инструментом для анализа и сравнения, позволяя выявить лучших в своем сегменте. Выбор правильного лидерборда может значительно улучшить вашу стратегию и повысить эффективность работы.
- Open LLM Leaderboard. Платформа компании Hugging Face, предназначенная для отслеживания, ранжирования и автоматической оценки новейших LLM и чат-ботов, представленных на одноимённом сайте. Использует оригинальную систему оценки языковых моделей EleutherAI, основанную на расчёте семи бенчмарков.
- Chatbot Arena Leaderboard. Ещё одна открытая платформа для оценки LLM на сайте Hugging Face. Работает по краудсорсинговой схеме. Здесь собраны более 200 тысяч отзывов реальных пользователей, позволяющих оценить языковые модели с помощью системы ранжирования Elo, подобной рейтингу, применяемому для расчёта уровня игры шахматистов.
Основная концепция Chatbot Arena Leaderboard заключается в попарном сравнении качества ответов моделей, осуществляемом людьми-асессорами с использованием рейтинга Elo. Существуют так называемые «мошеннические» методы, позволяющие моделям демонстрировать высокие результаты в бенчмарках, которые не всегда отражают их истинные показатели качества. В данной ситуации ручная оценка, основанная на простом сравнении, помогает частично решить эту проблему, обеспечивая более точное представление о реальных возможностях моделей.
Виктор Носко — это имя, которое связано с различными достижениями и проектами. Он известен своей экспертизой в определенных областях, что делает его востребованным специалистом. Виктор активно участвует в общественной жизни и делится своими знаниями через различные платформы. Его работы и инициативы направлены на развитие и поддержку молодежи, что подчеркивает его стремление к улучшению общества. Важно отметить, что вклад Виктора Носко в свою профессию и общество в целом создает положительный эффект и вдохновляет других на активные действия.
- AlpacaEval Leaderboard. Автоматическая система оценки языковых моделей, относящихся к классу Instruct. Основана на методике AlpacaFarm, которая проверяет способность LLM следовать общим инструкциям пользователя. В качестве «судьи» и источника эталонных ответов в ней используется ИИ на основе модели GPT-4.
- Chatbot Arena. Разработка LMSYS Org (Large Model Systems Organization) из Калифорнийского университета в Беркли, создавшей модель Vicuna-13B. Важно, что лидерборд не обновлялся с мая 2023 года.
- Big Code Models Leaderboard. Система оценки LLM, предназначенных для генерации программного кода. Очередная разработка Hugging Face. Лидерборд не обновлялся с ноября 2023 года, поэтому может содержать неактуальные данные.
Платформа Hugging Face занимает лидирующие позиции в области машинного обучения и обработки естественного языка. Она предлагает обширный набор бенчмарков, известных как The Big Benchmarks Collection. Благодаря этому пользователи могут легко настраивать рейтинги и выбирать оптимальные модели для решения конкретных задач, таких как написание кода. Hugging Face предоставляет удобные инструменты, которые упрощают процесс выбора и тестирования моделей, что делает ее идеальным решением для разработчиков и исследователей в сфере ИИ.
В данной области активны не только специализированные компании. Различные open-source-сообщества также стремятся разработать универсальную систему оценки, которая объединит лучшие черты всех существующих лидербордов. Примером такого подхода является проект LLM-Leaderboard, инициированный Людвигом Штумппом из Германии. Этот проект нацелен на создание единой платформы для оценки и сравнения языковых моделей, что может значительно облегчить исследователям и разработчикам выбор оптимальных решений для их задач.
Открытые модели машинного обучения показывают результаты, близкие к проприетарным в большинстве задач. Например, в задачах, связанных с ответами на вопросы или упрощением текстов, пользователи могут не заметить значительной разницы между LLaMA 2 70B и ChatGPT. Кроме того, разрыв в производительности между закрытыми и открытыми моделями продолжает уменьшаться, что делает открытые решения все более конкурентоспособными.
Михаил Сальников — профессионал в своей области, обладающий значительным опытом и знаниями. Его работа охватывает множество аспектов, что делает его ценным специалистом. Михаил постоянно совершенствует свои навыки, следит за новыми тенденциями и активно применяет их в своей практике. Его подход к делу основан на внимании к деталям и стремлении к высокому качеству. Сальников также делится своими знаниями с коллегами, что способствует развитию команды и повышению общей эффективности работы.
Михаил Сальников — это имя, которое ассоциируется с надежностью и профессионализмом. Его достижения в сфере деятельности вдохновляют многих, а его опыт служит примером для подражания.

Чтение является важной частью нашей жизни, предоставляя нам возможность расширять горизонты, получать новые знания и развивать мышление. Это увлечение не только развлекает, но и обогащает, открывая доступ к различным культурам и идеям. Регулярное чтение помогает улучшить словарный запас, развить аналитические навыки и повысить уровень концентрации. Независимо от того, предпочитаете ли вы художественную литературу, научные статьи или деловые книги, каждый жанр предлагает уникальные преимущества. Найдите время для чтения каждый день, и вы заметите положительные изменения в своем восприятии мира и уровне интеллекта.
Нейросети становятся все более популярными и актуальными в разных сферах жизни и бизнеса. В этом контексте представляем 30 мощных нейросетей, которые могут быть полезны для решения различных задач. Эти инструменты охватывают широкий спектр применения, от обработки естественного языка до генерации изображений и анализа данных. Использование нейросетей позволяет значительно повысить эффективность работы, автоматизировать процессы и получать ценные инсайты из больших объемов информации. Ознакомьтесь с нашими рекомендациями, чтобы выбрать подходящую нейросеть для ваших нужд и оптимизировать рабочие процессы.
Примеры популярных опенсорсных моделей
Основу большинства LLM с открытой лицензией составляют несколько ключевых моделей. Рассмотрим основные из них.
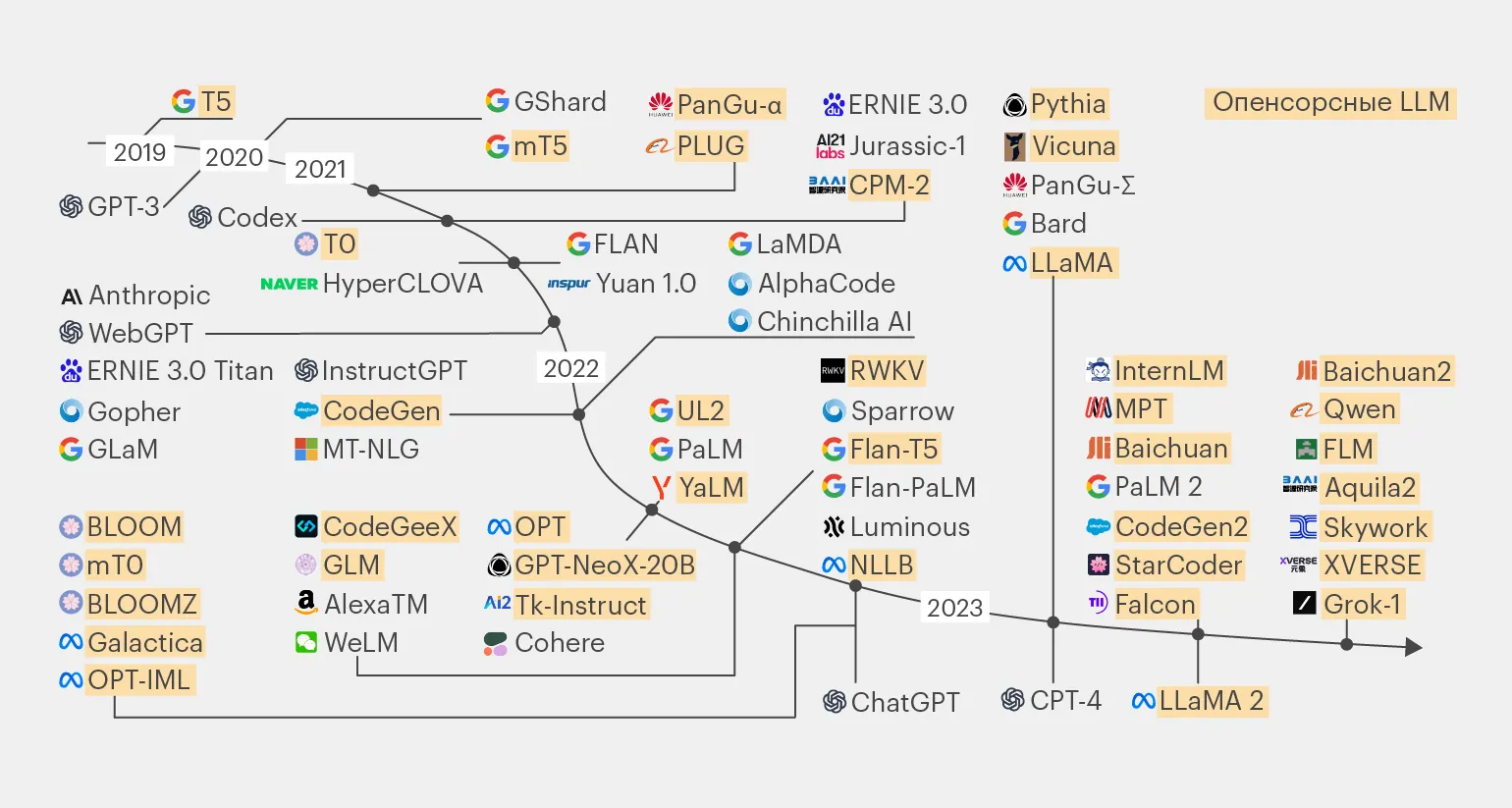
Модель LLaMA была представлена в феврале 2023 года и предлагает различные варианты с количеством параметров, равным 7, 13, 33 и 65 миллиардам. Особенностью первых двух версий является возможность их запуска на одном графическом процессоре, что стало настоящей сенсацией в момент релиза. Такие характеристики делают модель LLaMA доступной для широкого круга пользователей и разработчиков, что способствует её популярности в области искусственного интеллекта и обработки естественного языка.
В июле 2023 года была представлена обновленная версия LLaMA 2, созданная в партнерстве с Microsoft. Эта языковая модель (LLM) предлагает три варианта с количеством параметров: 7, 13 и 70 миллиардов. Улучшения в LLaMA 2 направлены на повышение эффективности обработки и генерации текста, что делает её востребованной в различных областях применения, от автоматизации до создания контента.
На базе модели LLaMA была разработана открытая версия OpenLLaMA, которая стала основой для многочисленных проектов. Эти проекты направлены на развитие модели через эксперименты с архитектурой, а также различные методы тонкой настройки и обучения. OpenLLaMA предоставляет исследователям и разработчикам возможность улучшать и адаптировать модель под специфические задачи, что способствует расширению её применения в различных областях.
LLaMA 2 70B представляет собой условно открытую модель, которая доступна с исходным кодом и весами. Однако ее использование в коммерческих целях ограничено: если число пользователей превышает 700 миллионов в месяц, это становится недопустимым. Эта модель занимает значительное место на рынке и является одной из самых известных после закрытых решений, таких как ChatGPT и Claude 2. LLaMA 2 70B демонстрирует высокие показатели производительности и качества, что делает ее привлекательной для разработчиков и исследователей в области искусственного интеллекта.
Михаил Сальников является известной фигурой в своей области. Его достижения и опыт вызывают интерес и уважение. Сальников активно занимается своей профессиональной деятельностью, делая значительный вклад в развитие отрасли. Его подход к работе и инновационные идеи вдохновляют многих коллег. Михаил Сальников — это имя, которое ассоциируется с качеством и надежностью, и его работа продолжает оказывать влияние на множество проектов и инициатив.
В 2023 году значительный прорыв в массовом использовании нейронных сетей с открытым исходным кодом обеспечила модель LLaMA. На ее основе были разработаны десятки новых моделей, среди которых Mistral, Zephyr, Alpaca, Phi-2, Qwen, Yi и многие другие. Эти разработки способствуют расширению возможностей применения нейронных сетей в различных сферах, включая обработку естественного языка, искусственный интеллект и машинное обучение. Важно отметить, что открытый код моделей позволяет исследователям и разработчикам использовать и улучшать технологии, что способствует быстрому прогрессу в области искусственного интеллекта.
Виктор Носко — известная личность в своей области. Он зарекомендовал себя как эксперт, обладающий глубокими знаниями и опытом. В своей деятельности Виктор Носко фокусируется на актуальных проблемах и предлагает эффективные решения. Его подход отличается уникальностью и инновационностью, что позволяет ему выделяться среди других специалистов. Благодаря своим достижениям, Виктор Носко стал авторитетом и источником вдохновения для многих. Его работы и идеи способствуют развитию и улучшению практик в данной области, что делает его вклад неоценимым.
В данной статье мы собрали мнения экспертов о популярных опенсорсных языковых моделях (LLM) из семейства LLaMA. Они выделили наиболее интересные модели, предоставив краткие характеристики и особенности каждой из них.
Обратите внимание на следующие открытые LLM (языковые модели), которые могут быть полезны для различных задач. Эти модели предоставляют доступ к передовым технологиям обработки естественного языка и могут эффективно использоваться в научных исследованиях, разработке программного обеспечения и создании контента. Открытые LLM предлагают пользователям возможность настраивать и адаптировать модели под свои нужды, что делает их универсальными инструментами для решения разнообразных задач в области искусственного интеллекта и машинного обучения. Рассмотрите возможность интеграции этих моделей в ваши проекты для повышения их эффективности и качества.
- Vicuna-13B от LMSYS Org — это одна из первых моделей с поддержкой русского языка, показывающая при этом неплохие результаты в остальных бенчмарках.
- Mistral — модель от одноимённого французского стартапа, превосходящая LLaMA 2 13B во всех бенчмарках. На конец сентября 2023 года была лучшей LLM с размером 7 млрд параметров.
- Zephyr-7B — это версия Mistral, прошедшая процедуру тонкой настройки (файн-тюнинга) с помощью метода Direct Preference Optimization (DPO). Имеет 90,6% частоту побед над другими нейронками в AlpacaEval Leaderboard.
- OpenChat — библиотека языковых моделей с открытым исходным кодом. По оценкам, она достигает качества ChatGPT (в версии от марта 2023 года), а также превосходит чат-бот Илона Маска Grok. Поддерживает русский язык. OpenChat 7B сделан на базе Mistral 7B, но в отличие от него проходит известный «тест на банан», который формулируется в виде вопроса к LLM: «Я на кухне, положил тарелку на банан. Затем я отнёс тарелку в спальню. Где сейчас банан?»
- Xwin-LM-70B-V0.1 — модель, созданная на базе LLaMA 2. Как утверждают разработчики, это первая модель, которая превзошла GPT-4 в бенчмарке AlpacaEval. Правда, размер у неё довольно большой — 70 миллиардов параметров».
Виктор Носко — это имя, которое заслуживает внимания в сфере своей деятельности. Он известен своими достижениями и вкладом в развитие различных проектов. Благодаря своему опыту и профессиональному подходу, Виктор Носко стал авторитетом в своей области. Его работа отражает высокие стандарты качества и стремление к постоянному совершенствованию. Если вы ищете надежного эксперта или партнера, Виктор Носко — это тот, на кого можно положиться.
Mistral 7B привлекает внимание благодаря тому, что, обладая всего 7 миллиардами параметров, она демонстрирует более высокие результаты по сравнению с LLaMA 2, которая имеет 13 миллиардов параметров. Это делает модель доступной для использования на большинстве современных ноутбуков, что расширяет возможности её применения в различных задачах.
Рекомендую обратить внимание на модель Dolly от американской компании Databricks. Несмотря на то, что она не является родственницей LLaMA и основана на семействе EleutherAI Pythia, её открытость предоставляет уникальные возможности. Модель полностью доступна для использования в различных целях, что является её ключевым преимуществом. Это делает Dolly привлекательным выбором для разработчиков и исследователей, стремящихся к применению мощных инструментов в своих проектах.
Михаил Сальников — это имя, которое стало известным в определенных кругах благодаря его достижениям и вкладу в свою область. Он зарекомендовал себя как профессионал, обладающий глубокими знаниями и опытом. Сальников активно участвует в различных проектах, что позволяет ему оставаться на передовой в своей сфере. Его работы отмечены высоким качеством и инновационными подходами, что делает его ценным специалистом. Важно отметить, что Михаил постоянно стремится к самосовершенствованию и изучению новых тенденций, что позволяет ему быть конкурентоспособным на рынке. Сальников является примером того, как можно добиться успеха благодаря упорству и профессионализму.
В России активно разрабатываются собственные модели языкового обучения (LLM), специально адаптированные для работы с русским языком. Эти технологии направлены на улучшение взаимодействия с пользователями и повышение качества обработки текстовой информации на русском. Создание таких моделей позволит значительно продвинуться в области искусственного интеллекта и машинного обучения, а также обеспечить поддержку локальных потребностей и специфики языка.
Среди российских разработок искусственного интеллекта стоит отметить ruGPT-3.5, которая является основой для GigaChat от Сбера. В открытом доступе представлена только предобученная версия, что означает необходимость самостоятельного дообучения для достижения оптимальных результатов.
Разработка Сбербанка сталкивается с конкуренцией со стороны модели YaGPT 2 от Яндекса, которая пока не доступна для широкой публики. В 2022 году Яндекс представил предшественницу этой модели, YaLM 100B, которая была выпущена под лицензией Apache 2.0. Эта модель уже привлекла внимание специалистов и исследователей в области искусственного интеллекта благодаря своим впечатляющим характеристикам и возможностям. Конкуренция между Сбером и Яндексом в области AI технологий подчеркивает растущий интерес к разработке инновационных решений, способных трансформировать различные сферы бизнеса и повседневной жизни.
Среди российских LLM выделяется модель Saiga 2, разработанная инженером по машинному обучению Ильей Гусевым. Эта модель позиционируется как «российский чат-бот», основанный на архитектурах LLaMA 2 и Mistral. Saiga 2 предлагает уникальные возможности для взаимодействия с пользователями, обеспечивая высокое качество ответов и адаптивность к различным запросам. Интерес к таким моделям растет, так как они способствуют развитию технологий обработки естественного языка в России.
Основная отечественная разработка в области искусственного интеллекта — это ruGPT-3.5, на базе которой был создан GigaChat. Это решение является одним из лучших для русскоязычного контента на данный момент. Кроме того, стоит отметить YandexGPT, которая также демонстрирует высокую эффективность в работе с русским языком. Однако на текущий момент разработчики не предоставили открытого доступа к модели YandexGPT, что ограничивает её использование.
Михаил Сальников — это имя, которое вызывает интерес в различных областях. Важно отметить, что Михаил Сальников может быть связан с несколькими сферами деятельности, включая искусство, науку и бизнес. Если вы ищете информацию о Михаиле Сальникове, вам стоит учитывать его достижения и вклад в избранную область. Это имя может быть связано с творчеством, инновациями или предпринимательством. В зависимости от контекста, Михаил Сальников представляет собой личность, которая оставила заметный след.
В области больших языковых моделей (LLM) выделяется направление, посвященное обучению нейронных сетей написанию программного кода. В настоящее время имеется несколько востребованных опенсорсных моделей, которые активно используются для этой цели. Эти модели позволяют разработчикам автоматизировать процесс написания кода, улучшая производительность и сокращая время разработки. Оптимизация программного обеспечения с помощью нейросетей открывает новые горизонты в программировании, делая его более доступным и эффективным.
- StableCode от StabilityAI, создавшей Stable Diffusion. Может программировать на Python, Java, Go, JavaScript, C, и C++.
- StarCoder — это набор моделей с 15,5 миллиардами параметров, обученных на более чем 80 языках программирования.
- SantaCoder — серия моделей с размером 1,1 миллиард параметров, созданных на базе GPT-2. Обучена генерировать код на языках Python, Java и JavaScript.
- CodeGeeX и CodeGeeX2 от китайских специалистов. Первая версия нейронки на 13 миллиардов параметров была обучена на 20 языках программирования, вторая — с размером 6 миллиардов — умеет кодить уже на 100 языках. Среди них Python, Java, C++, C#, JavaScript, PHP и Go. Может быть подключена в виде плагина к популярным IDE: Visual Studio Code, IntelliJ IDEA и Android Studio.
- Replit Code — языковая модель размером 2,7 миллиарда параметров, обученная на автодополнение кода. Обучалась на наборах данных, содержащих 20 языков, включая Java, JavaScript, Python и PHP.
- CodeT5 и CodeT5+. Семейство моделей от американской компании Salesforce Research. Как следует из названия, LLM основана на базовой открытой модели T5. Есть варианты на 220 миллионов, 770 миллионов, 2 миллиарда, 6 миллиардов и 16 миллиардов параметров. Способна кодить на Ruby, JavaScript, Python, Java, PHP, C, C++, C#.
- CodeGen2 и CodeGen2.5 — ещё одно семейство опенсорсных LLM с типоразмерами на 1, 3,7, 7 и 16 миллиардов параметров от той же Salesforce Research.
- DeciCoder 1B — скромная моделька с 1 миллиардом параметров, которая умеет завершать предложенные человеком фрагменты программного кода. Обучена на языках Python, Java и JavaScript. При этом, по заверениям разработчиков, «обеспечивает увеличение производительности в 3,5 раза, повышенную точность в тесте HumanEval и меньшее использование памяти по сравнению с широко используемыми LLM для генерации кода, такими как SantaCoder».
- Code LLaMA — версия LLaMA 2, прошедшая дообучение для работы с программным кодом. Имеет варианты на 7, 13 и 34 миллиарда параметров. Справляется с Python, C++, Java, PHP, C# и TypeScript.

Читайте также:
Современные нейросети становятся незаменимыми инструментами для программистов, позволяя значительно ускорить процесс написания кода и повысить его качество. В этой статье мы рассмотрим семь наиболее популярных нейросетей, которые помогут разработчикам в их работе. Использование этих технологий не только упрощает выполнение рутинных задач, но и способствует улучшению кода за счет автоматизированной проверки и оптимизации.
С помощью нейросетей программисты могут генерировать код, исправлять ошибки и предлагать лучшие решения для различных задач. Эти инструменты способны анализировать огромные объемы данных, что позволяет находить оптимальные алгоритмы и подходы. Интеграция нейросетей в рабочий процесс помогает разработчикам сосредоточиться на более креативных аспектах программирования, оставляя рутинные задачи на откуп искусственному интеллекту.
Используя нейросети, программисты могут не только повысить свою продуктивность, но и улучшить качество конечного продукта. В результате, разработка становится более эффективной, а конечные решения — более надежными и оптимальными. Таким образом, нейросети открывают новые горизонты для программистов, позволяя им достигать лучших результатов за меньшее время.
Что ещё почитать
В данной статье представлен обзор по обширной теме опенсорсных языковых моделей. Если вы хотите глубже разобраться в мире открытых и проприетарных языковых моделей (LLM), рекомендуем ознакомиться с двумя исследовательскими работами, опубликованными на портале arxiv.org. Эти работы предоставляют ценные данные и анализ, которые помогут лучше понять текущие тенденции и технологии в области языковых моделей.
- A Survey of Large Language Models.
- Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond.
Следить за последними обновлениями в мире опенсорсных LLM можно на платформе GitHub и других специализированных ресурсах. Регулярные подборки и обновления помогут вам быть в курсе новых разработок и улучшений в области языковых моделей с открытым исходным кодом. Это позволит вам не только отслеживать тренды, но и участвовать в сообществе, обмениваться опытом и получать актуальную информацию о возможностях использования LLM.
- Список открытых LLM, доступных для коммерческого использования.
- Коллекция открытых и проприетарных LLM.
- Список больших языковых моделей.
- Коллекция китайских моделей с открытым исходным кодом.
- Краткое руководство по наборам данных для тонкой настройки моделей.
Мы будем информировать вас о ключевых новостях в области искусственного интеллекта и о событиях, связанных с сообществом Open Source, в нашем телеграм-канале. Подписывайтесь, чтобы быть в курсе последних трендов и технологий в этих динамично развивающихся сферах.
Переделанный текст:
Изучите дополнительные материалы:
- 10 мифов о свободном ПО
- Вы находитесь здесь: итоги 2023 года в сфере ИИ
- Что ждёт IT-специалистов в новом 2024 году: прогнозы и пожелания от лучших нейросетей
Судом принято решение о запрете деятельности компании Meta Platforms Inc. на территории Российской Федерации в отношении реализации социальных сетей Facebook и Instagram. Это решение было принято на основе обвинений в осуществлении экстремистской деятельности.
